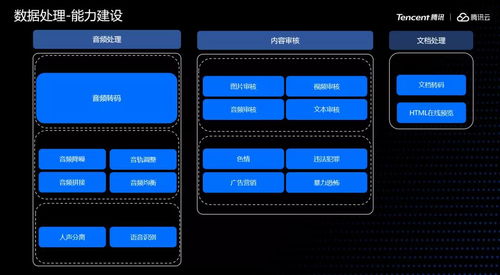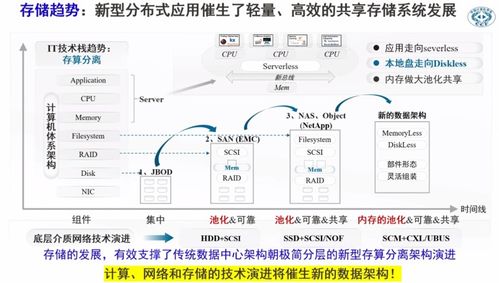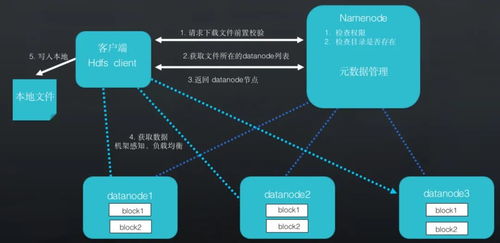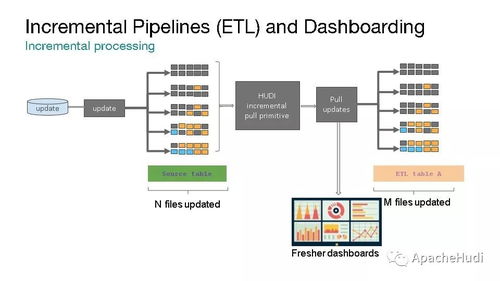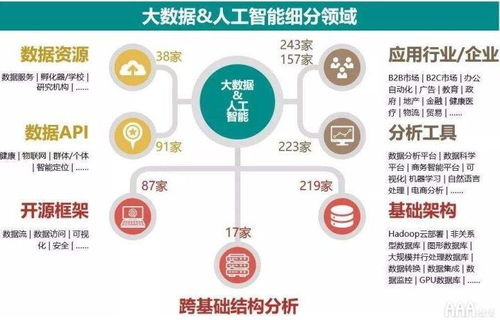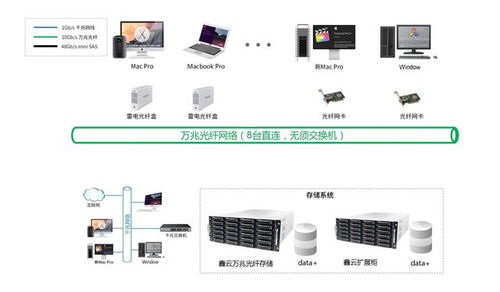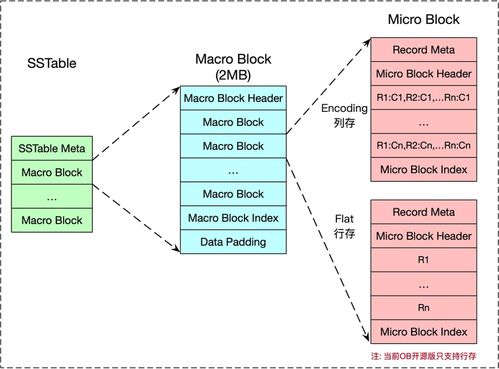
在人工智能浪潮席卷全球的今天,深度學習模型的開發與訓練已成為推動技術進步的核心驅動力。從海量數據中提取價值、構建并迭代復雜模型的過程,往往伴隨著巨大的計算資源消耗、繁瑣的運維管理和數據處理的復雜性。為了應對這些挑戰,業界領先的深度學習框架 PaddlePaddle(飛槳) 與云原生容器編排領域的王者 Kubernetes(K8s) 展開了深度協同,共同為開發者打造了一套高效、彈性、可擴展的模型訓練與數據處理解決方案,顯著降低了AI應用落地的門檻。
一、強強聯合:PaddlePaddle 與 Kubernetes 的協同優勢
PaddlePaddle 作為百度開源、國內首個自主研發的產業級深度學習平臺,以其開發便捷的框架、豐富的模型庫、高效的分布式訓練能力和端到端的部署工具鏈而聞名。它旨在讓開發者能夠更輕松地將創意轉化為實際應用。
Kubernetes 則是一個開源的容器編排系統,它自動化了容器化應用程序的部署、擴展和管理。其核心價值在于提供了強大的資源調度、服務發現、彈性伸縮和故障恢復能力,確保應用能夠穩定、高效地運行在復雜的集群環境中。
當 PaddlePaddle 的深度學習能力與 Kubernetes 的云原生基礎設施管理能力相結合,便產生了奇妙的化學反應:
- 資源利用最大化:Kubernetes 可以智能調度 PaddlePaddle 訓練任務到集群中最合適的計算節點(如GPU服務器),實現CPU、內存、GPU等資源的精細化管理和高效利用,避免資源閑置或爭搶。
- 訓練任務彈性伸縮:面對不同規模的數據集和模型,開發者可以輕松地通過 Kubernetes 動態調整訓練任務的并行度(Worker數量)。無論是需要啟動上百個節點的超大規模分布式訓練,還是臨時增加資源以加速實驗,都能一鍵完成,極具彈性。
- 簡化運維與高可用:Kubernetes 自動管理訓練任務的生命周期,包括自動重啟失敗的任務、健康檢查、滾動更新等。開發者無需再手動監控和管理每一個訓練進程,可以將精力集中于算法和模型本身。
- 標準化與可移植性:容器化將 PaddlePaddle 的運行環境、依賴庫和代碼打包成一個標準鏡像。結合 Kubernetes,這套訓練流水線可以在任何支持 K8s 的云環境或私有數據中心中無縫運行,實現了“一次構建,隨處運行”。
二、核心助力:高效訓練與數據處理存儲服務
本次聯手對開發者的助力,核心體現在兩個緊密相關的環節:模型訓練 與 數據處理/存儲。
高效模型訓練服務
通過 PaddlePaddle 的分布式訓練能力(如 Fleet API)與 Kubernetes 的編排能力深度集成,可以實現:
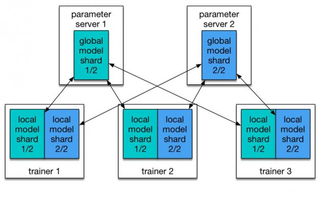
- 一鍵式分布式訓練:開發者只需定義好訓練任務和所需的資源規格,Kubernetes 即可自動創建和管理一組訓練 Pod(容器組),其中包括參數服務器和多個訓練工作節點,快速啟動大規模分布式訓練。
- 混合調度與異構計算:Kubernetes 可以調度任務到混合架構的集群(如不同型號的GPU、CPU機器),PaddlePaddle 能夠利用這些異構資源進行訓練,提供了極大的靈活性。
- 實驗管理與流水線:結合 Kubeflow 等基于 K8s 的 MLOps 工具,可以構建完整的機器學習流水線,實現從數據預處理、模型訓練、超參調優到模型評估的自動化,極大提升團隊協作效率和實驗可復現性。
統一的數據處理與存儲服務
模型訓練的效率嚴重依賴于數據供給的“管道”。PaddlePaddle 與 Kubernetes 生態的結合,為數據層提供了強大支持:
- 持久化存儲集成:Kubernetes 支持多種持久卷(Persistent Volume)類型,如網絡存儲(NFS、Ceph、云盤等)。訓練任務可以輕松掛載這些存儲卷,實現訓練數據的集中式、高可用存儲,數據在任務銷毀后依然保留。
- 高性能緩存與加速:對于超大規模數據集,可以結合 Alluxio、Fluid 等云原生數據編排系統,在計算集群內部構建分布式緩存層,將遠程存儲的數據緩存在本地或高速 SSD 上,為 PaddlePaddle 訓練任務提供內存級的數據訪問速度,徹底消除 I/O 瓶頸。
- 數據預處理容器化:將數據清洗、增強、格式轉換等預處理步驟也封裝為容器化任務,在 Kubernetes 上作為訓練流水線的一個前置步驟運行。這使得復雜的數據處理流程也能享受資源的彈性調度和標準化的管理。
- 統一數據訪問接口:無論數據存放在對象存儲、HDFS 還是本地,通過相應的 CSI 驅動或客戶端庫,PaddlePaddle 訓練程序都能以近乎一致的方式進行訪問,簡化了代碼復雜度。
三、開發者體驗與未來展望
對于開發者而言,這種集成意味著他們可以從繁瑣的基礎設施管理中解放出來,獲得一個“唾手可得”的、企業級的 AI 研發平臺。他們能夠:
- 更快地開始實驗:通過預制的容器鏡像和 Kubernetes 部署清單,快速搭建訓練環境。
- 更放心地運行長時任務:依托 K8s 的穩定性,安心進行長達數天甚至數周的模型訓練。
- 更高效地利用資源:按需申請計算資源,按量計費,顯著降低研發成本。
- 更順暢地協同與交付:標準化的環境使得模型從研發到生產部署的路徑更加順暢。
隨著 PaddlePaddle 的持續演進和 Kubernetes 生態的日益繁榮,兩者的結合將更加緊密。我們有望看到更多開箱即用的 Operator(例如 PaddlePaddle Operator)來進一步簡化部署,更智能的自動擴縮容策略,以及與邊緣計算場景的深度融合,為 AI 技術在千行百業的落地提供無處不在的強勁算力和數據服務支撐。
PaddlePaddle 與 Kubernetes 的聯手,不僅是技術的融合,更是為 AI 開發者構建了一條通往高效生產力和創新成功的“高速公路”。它正推動著深度學習模型的開發從手工作坊模式,邁向標準化、自動化、規模化的工業級生產新時代。