Elasticsearch(簡稱ES)作為一種開源的分布式搜索和分析引擎,廣泛應用于數(shù)據(jù)處理與存儲服務中。其核心優(yōu)勢在于高效的全文檢索、實時數(shù)據(jù)分析和大規(guī)模數(shù)據(jù)存儲能力。以下將詳細介紹ES的數(shù)據(jù)存儲與查詢基本原理,并探討其在現(xiàn)代數(shù)據(jù)處理與存儲服務中的關鍵作用。
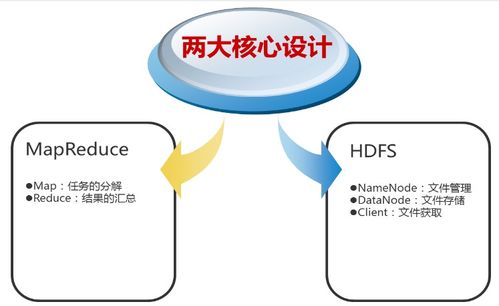
一、ES數(shù)據(jù)存儲基本原理
ES基于Apache Lucene構建,采用分布式架構存儲數(shù)據(jù),具有高可擴展性和容錯性。其存儲機制主要包括以下方面:
- 索引(Index)與文檔(Document)結構:
- 索引是ES中數(shù)據(jù)的邏輯容器,類似于傳統(tǒng)數(shù)據(jù)庫中的表。每個索引包含多個文檔,文檔是基本的數(shù)據(jù)單元,以JSON格式存儲。
- 文檔通過唯一ID標識,并自動或手動分配到索引的分片中。
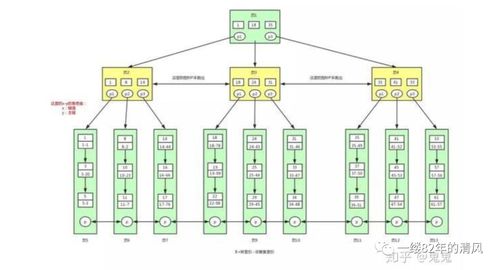
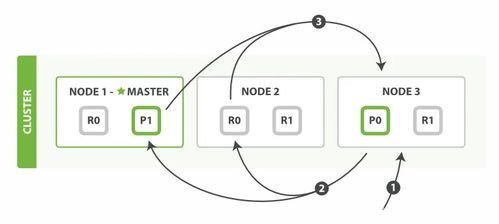
- 分片(Shard)與副本(Replica)機制:
- 索引被劃分為多個分片,每個分片是一個獨立的Lucene索引,分布在集群的不同節(jié)點上。這支持水平擴展,允許數(shù)據(jù)分布在多臺機器上。
- 副本是分片的復制品,提供數(shù)據(jù)冗余和高可用性。當主分片故障時,副本可自動接管,確保服務不中斷。
- 倒排索引(Inverted Index):
- ES使用倒排索引實現(xiàn)快速全文檢索。倒排索引將文檔中的詞條映射到包含該詞條的文檔列表,類似于書籍的索引頁。
- 在數(shù)據(jù)寫入時,ES對文本進行分析(如分詞、小寫化),并構建倒排索引,從而在查詢時快速定位相關文檔。
- 數(shù)據(jù)寫入與持久化流程:
- 當文檔寫入時,ES首先將其添加到內存緩沖區(qū),然后定期刷新(refresh)到文件系統(tǒng)緩存,形成可搜索的段(segment)。
- 為了確保數(shù)據(jù)持久性,ES通過事務日志(translog)記錄操作,并定期執(zhí)行段合并(merge)和刷新到磁盤。
二、ES數(shù)據(jù)查詢基本原理
ES的查詢功能強大,支持多種查詢類型,從簡單匹配到復雜聚合分析。其查詢流程如下:
- 查詢解析與分發(fā):
- 客戶端發(fā)送查詢請求到協(xié)調節(jié)點,協(xié)調節(jié)點解析查詢(如使用Query DSL),并根據(jù)索引分片位置將請求分發(fā)到相關節(jié)點。
- 查詢可以包括過濾、排序、分頁和高亮等參數(shù)。
- 查詢執(zhí)行與評分:
- 每個分片獨立執(zhí)行查詢,使用倒排索引快速匹配文檔,并計算相關性評分(如TF-IDF或BM25算法)。
- 對于聚合查詢,ES在分片級別執(zhí)行初步聚合,然后在協(xié)調節(jié)點合并結果。
- 結果合并與返回:
- 協(xié)調節(jié)點收集各分片的查詢結果,進行排序、評分合并和分頁處理,最終返回給客戶端。
- ES支持近實時(NRT)搜索,數(shù)據(jù)寫入后通常在1秒內可被查詢。
三、ES在數(shù)據(jù)處理與存儲服務中的應用
在數(shù)據(jù)處理與存儲服務中,ES扮演著關鍵角色,特別適用于日志分析、監(jiān)控系統(tǒng)和搜索引擎等場景:
- 實時數(shù)據(jù)處理:ES能夠處理流式數(shù)據(jù),如應用日志或傳感器數(shù)據(jù),提供實時索引和查詢能力。結合Kibana等工具,可實現(xiàn)數(shù)據(jù)可視化。
- 高可用性與擴展性:通過分片和副本機制,ES服務可以輕松擴展以處理PB級數(shù)據(jù),同時保證高可用性,適合企業(yè)級存儲需求。
- 復雜查詢支持:ES支持全文檢索、地理位置查詢和聚合分析,使其在數(shù)據(jù)分析服務中優(yōu)于傳統(tǒng)數(shù)據(jù)庫。例如,在電商平臺中,可實現(xiàn)商品搜索和用戶行為分析。
- 集成生態(tài)系統(tǒng):ES常與Logstash和Beats等工具集成,形成ELK棧(Elastic Stack),提供端到端的數(shù)據(jù)采集、存儲和查詢解決方案。
Elasticsearch通過其高效的存儲和查詢機制,為現(xiàn)代數(shù)據(jù)處理與存儲服務提供了強大支持。理解其基本原理有助于優(yōu)化數(shù)據(jù)架構,提升系統(tǒng)性能和可靠性。在實際應用中,建議根據(jù)數(shù)據(jù)規(guī)模和查詢需求合理配置索引、分片和副本,以實現(xiàn)最佳效果。