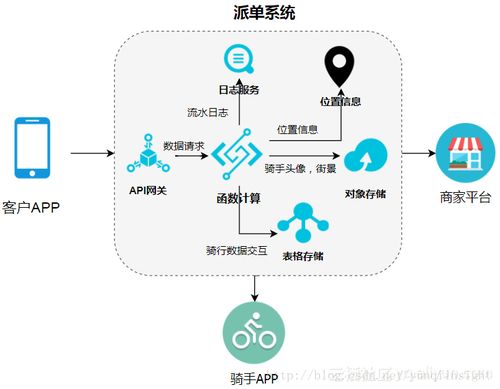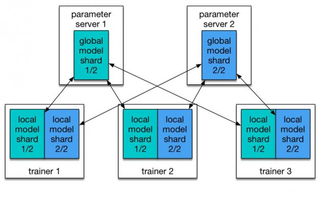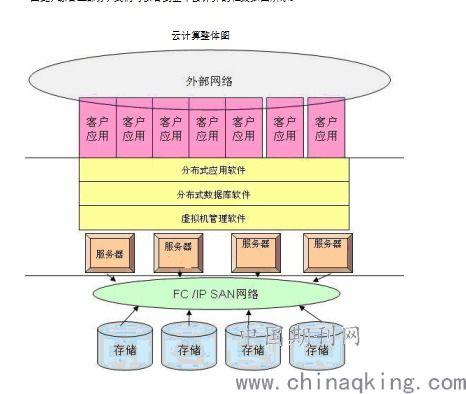
在當今數(shù)據(jù)驅(qū)動的時代,企業(yè)如何高效、安全地處理與存儲海量數(shù)據(jù),已成為數(shù)字化轉(zhuǎn)型的核心挑戰(zhàn)。微軟 Azure 作為領(lǐng)先的云服務(wù)平臺,提供了一系列強大、靈活且集成的數(shù)據(jù)處理與存儲服務(wù),幫助企業(yè)從數(shù)據(jù)中挖掘價值,驅(qū)動創(chuàng)新。本文將深入探索 Azure 在數(shù)據(jù)處理與存儲領(lǐng)域的關(guān)鍵服務(wù)及其應(yīng)用場景。
一、 Azure 數(shù)據(jù)存儲服務(wù):構(gòu)建可靠的數(shù)據(jù)基石
Azure 的數(shù)據(jù)存儲服務(wù)覆蓋了從結(jié)構(gòu)化到非結(jié)構(gòu)化數(shù)據(jù)的全方位需求,每種服務(wù)都針對特定的數(shù)據(jù)模式和訪問模式進行了優(yōu)化。
- Azure Blob Storage:作為對象存儲解決方案,它是存儲海量非結(jié)構(gòu)化數(shù)據(jù)(如圖片、視頻、文檔、日志文件及備份數(shù)據(jù))的理想選擇。其提供了熱、冷、存檔三種訪問層級,能顯著優(yōu)化存儲成本。
- Azure Data Lake Storage Gen2:專為大數(shù)據(jù)分析而設(shè)計,它結(jié)合了 Blob Storage 的高性價比和文件系統(tǒng)的目錄層次結(jié)構(gòu)。它原生支持 Hadoop 分布式文件系統(tǒng)(HDFS)協(xié)議,是運行 Azure Databricks、HDInsight 和 Synapse Analytics 等分析服務(wù)的首選底層存儲。
- Azure SQL Database:完全托管的智能關(guān)系數(shù)據(jù)庫服務(wù),基于 SQL Server 引擎。它提供了自動調(diào)優(yōu)、高可用性和內(nèi)置智能安全功能,是運行關(guān)鍵業(yè)務(wù)在線事務(wù)處理(OLTP)應(yīng)用程序的可靠選擇。
- Azure Cosmos DB:全球分布的多模型數(shù)據(jù)庫服務(wù)。它提供對 NoSQL 數(shù)據(jù)的超低延遲訪問,并保證吞吐量和延遲的 SLA。其多 API 支持(如 SQL、MongoDB、Cassandra)使得遷移和開發(fā)現(xiàn)代應(yīng)用程序變得異常靈活。
- Azure Files:提供完全托管的云文件共享,可通過行業(yè)標準的服務(wù)器消息塊(SMB)協(xié)議訪問。它非常適合“直接遷移”場景,替代或補充本地文件服務(wù)器。
二、 Azure 數(shù)據(jù)處理與分析服務(wù):從數(shù)據(jù)到洞察
擁有可靠的數(shù)據(jù)存儲后,下一步是處理和分析這些數(shù)據(jù)以獲取洞察。Azure 提供了一套完整的工具鏈。
- Azure Synapse Analytics:這是一個集成的分析服務(wù),將企業(yè)數(shù)據(jù)倉庫和大數(shù)據(jù)分析融為一體。它允許用戶使用無服務(wù)器或?qū)S觅Y源,通過 T-SQL 查詢數(shù)據(jù)倉庫中的數(shù)據(jù),或使用 Spark 處理大數(shù)據(jù),并利用 Pipelines 進行數(shù)據(jù)集成。
- Azure Databricks:基于 Apache Spark 的快速、簡單、協(xié)同的分析平臺。它為數(shù)據(jù)工程師、數(shù)據(jù)科學(xué)家和業(yè)務(wù)分析師提供了一個協(xié)同工作空間,用于運行大規(guī)模數(shù)據(jù)工程、數(shù)據(jù)科學(xué)和機器學(xué)習工作負載。
- Azure HDInsight:一個完全托管的開源分析服務(wù),支持如 Hadoop、Spark、Kafka、HBase 等流行框架。它使得企業(yè)能夠輕松地在云中運行和管理這些開源集群。
- Azure Data Factory:云中的數(shù)據(jù)集成服務(wù)。它可以創(chuàng)建、調(diào)度和編排數(shù)據(jù)驅(qū)動的工作流(管道),從各種來源提取數(shù)據(jù),進行轉(zhuǎn)換處理,然后將結(jié)果發(fā)布到目標數(shù)據(jù)存儲中,是實現(xiàn) ETL/ELT 流程的核心。
- Azure Stream Analytics:實時事件處理引擎,用于分析從設(shè)備、傳感器、網(wǎng)站、應(yīng)用程序等產(chǎn)生的高吞吐量數(shù)據(jù)流。它可以幫助用戶實時檢測模式、觸發(fā)警報或構(gòu)建儀表板。
三、 架構(gòu)模式與最佳實踐
成功利用 Azure 數(shù)據(jù)處理與存儲服務(wù)的關(guān)鍵在于合理的架構(gòu)設(shè)計。常見的模式包括:
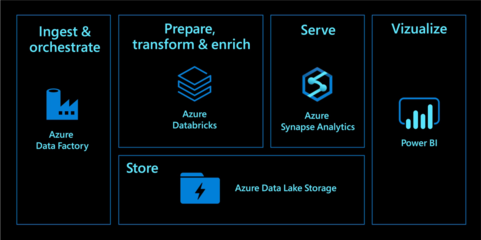
- 現(xiàn)代數(shù)據(jù)倉庫模式:使用 Azure Data Factory 將來自操作系統(tǒng)的數(shù)據(jù)攝取到 Azure Data Lake Storage Gen2 中,然后使用 Azure Databricks 或 Synapse Spark 池進行數(shù)據(jù)清洗和轉(zhuǎn)換,最后將精煉的數(shù)據(jù)加載到 Azure Synapse Analytics 的專用 SQL 池中,供 BI 工具(如 Power BI)進行查詢和分析。
- Lambda 架構(gòu):結(jié)合批處理和流處理。使用 Azure Stream Analytics 處理實時流數(shù)據(jù),提供低延遲視圖;同時使用 Azure Databricks 或 HDInsight 對存儲在 Data Lake 中的全量數(shù)據(jù)進行批處理,提供準確、完整的視圖。兩者結(jié)果在服務(wù)層合并。
- 安全與治理:利用 Azure Purview 建立統(tǒng)一的數(shù)據(jù)治理解決方案,實現(xiàn)跨本地、多云和 SaaS 的數(shù)據(jù)發(fā)現(xiàn)、分類和譜系追蹤。所有服務(wù)都應(yīng)集成 Azure Active Directory 進行身份驗證,并利用加密、虛擬網(wǎng)絡(luò)服務(wù)終結(jié)點和專用鏈接來確保數(shù)據(jù)安全。
###
Azure 的數(shù)據(jù)處理與存儲生態(tài)系統(tǒng)以其全面性、集成性和企業(yè)級可靠性,為組織構(gòu)建從數(shù)據(jù)湖到數(shù)據(jù)倉庫,從實時分析到機器學(xué)習的端到端解決方案提供了堅實的基礎(chǔ)。通過根據(jù)數(shù)據(jù)特性、訪問模式和業(yè)務(wù)目標選擇合適的服務(wù)組合,企業(yè)可以構(gòu)建出既高效又經(jīng)濟的數(shù)據(jù)平臺,從而真正釋放數(shù)據(jù)的潛能,贏得競爭優(yōu)勢。探索和駕馭這些服務(wù),正是邁向智能化未來的關(guān)鍵一步。